
Research Projects
As we forge ahead into an era of rapidly evolving Artificial Intelligence and Machine Learning, Large Language Models (LLMs), Vision Language Models (VLMs), and generative AI are becoming increasingly intertwined with our lives. These powerful tools hold the potential to revolutionize countless domains – from healthcare to transportation, education to entertainment, our workspaces to our homes. But this immense potential does not come without its perils.
We have witnessed instances where AI/ML models have fallen short of our expectations due to lack of robustness, efficiency, and fairness. For instance, the AI chatbot ‘Tay’ by Microsoft began to parrot offensive and inappropriate content, becoming a striking example of AI susceptibility to spurious features. Similarly, self-driving cars have shown vulnerability to adversarial perturbations – simple stickers strategically placed on stop signs have deceived these AI models into misclassifying them. Moreover, many AI models have faltered when faced with distribution shifts, failing to generalize their learning from training to real-world conditions, as evidenced by AI’s frequently documented struggles with recognizing faces from underrepresented groups. These models’ efficiency is another critical concern in the age of proliferating AI applications. With computational resources and data privacy being significant constraints, we need models that are lean and data-efficient. The recent Transformer models, despite their impressive capabilities, are notorious for their demand for computational resources and extensive training data, bringing us to a pressing need for efficient model design, data utilization, and learning processes. Additionally, as AI models continue to influence decision-making in crucial areas like healthcare, recruitment, and law enforcement, fairness has emerged as a non-negotiable requirement. Long-term fairness is especially challenging to achieve, as these AI systems often encounter evolving data distributions over time, which may lead to a drift from their fairness criteria.
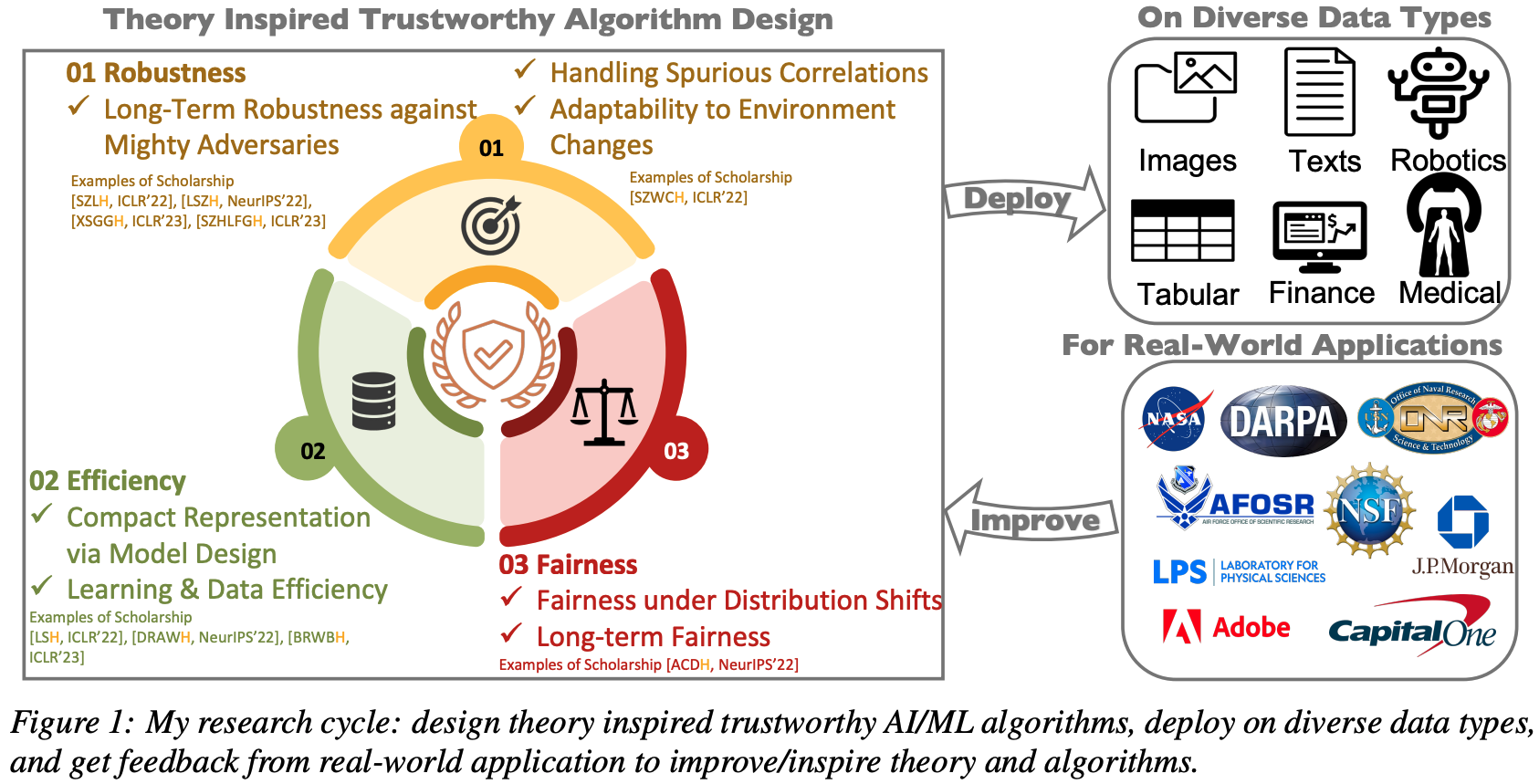
In the face of these challenges, my research stands at the forefront, focusing on robustness, efficiency, and fairness in AI/ML models, vital in fostering an era of Trustworthy AI that society can rely on. My research fortifies models against spurious features, adversarial perturbations, and distribution shifts, enhances model, data, and learning efficiency, and ensures long-term fairness under distribution shifts.
With academic and industrial collaborators, my research has been used for cataloguing brain cell types, learning human disease hierarchy, designing non-addictive pain killers, controlling power-grid for resiliency, defending against adversarial entities in financial markets, updating/finetuning industrial-scale model efficiently and etc.
Generative AI & LLMs

WAVES: Benchmarking the Robustness of Image Watermarks
This project investigates the weaknesses of image watermarking techniques. We present WAVES (Watermark Analysis Via Enhanced Stress-testing), a novel benchmark for assessing watermark robustness, overcoming the limitations of current evaluation methods.WAVES integrates detection and identification tasks, and establishes a standardized evaluation protocol comprised of a diverse range of stress tests. The attacks in WAVES range from traditional image distortions to advanced and novel variations of diffusive, and adversarial attacks. Our evaluation examines two pivotal dimensions: the degree of image quality degradation and the efficacy of watermark detection after attacks. We develop a series of Performance vs. Quality 2D plots, varying over several prominent image similarity metrics, which are then aggregated in a heuristically novel manner to paint an overall picture of watermark robustness and attack potency. Our comprehensive evaluation reveals previously undetected vulnerabilities of several modern watermarking algorithms. We envision WAVES as a toolkit for the future development of robust watermarking systems.
The project page is available at: https://wavesbench.github.io/
The link to paper: https://arxiv.org/abs/2401.08573
The link to code: https://github.com/umd-huang-lab/WAVES
The link to data on Hugging Face: https://huggingface.co/collections/furonghuang-lab/waves-65ac9e95356bf23b4a28d452
The link to visualization: https://wavesbench.github.io/#visualize-2d-plots
The link to Leaderboard: https://wavesbench.github.io/#leaderboard-watermark
AutoDAN: Interpretable Gradient-Based Adversarial Attacks on Large Language Models
Safety alignment of Large Language Models (LLMs) can be compromised with manual jailbreak attacks and (automatic) adversarial attacks. Recent studies suggest that defending against these attacks is possible: adversarial attacks generate unlimited but unreadable gibberish prompts, detectable by perplexity-based filters; manual jailbreak attacks craft readable prompts, but their limited number due to the necessity of human creativity allows for easy blocking. In this paper, we show that these solutions may be too optimistic. We introduce AutoDAN, an interpretable, gradient-based adversarial attack that merges the strengths of both attack types. Guided by the dual goals of jailbreak and readability, AutoDAN optimizes and generates tokens one by one from left to right, resulting in readable prompts that bypass perplexity filters while maintaining high attack success rates. Notably, these prompts, generated from scratch using gradients, are interpretable and diverse, with emerging strategies commonly seen in manual jailbreak attacks. They also generalize to unforeseen harmful behaviors and transfer to black-box LLMs better than their unreadable counterparts when using limited training data or a single proxy model. Furthermore, we show the versatility of AutoDAN by automatically leaking system prompts using a customized objective. Our work offers a new way to red-team LLMs and understand jailbreak mechanisms via interpretability.
Post on Social MediaHallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination & Visual Illusion in Large Vision-Language Models
We introduce HallusionBench, a comprehensive benchmark designed for the evaluation of image-context reasoning. This benchmark presents significant challenges to advanced large visual-language models (LVLMs), such as GPT-4V(Vision) and LLaVA-1.5, by emphasizing nuanced understanding and interpretation of visual data. The benchmark comprises 346 images paired with 1129 questions, all meticulously crafted by human experts. We introduce a novel structure for these visual questions designed to establish control groups. This structure enables us to conduct a quantitative analysis of the models' response tendencies, logical consistency, and various failure modes. In our evaluation on HallusionBench, we benchmarked 13 different models, highlighting a 31.42% question-pair accuracy achieved by the state-of-the-art GPT-4V. Notably, all other evaluated models achieve accuracy below 16%. Moreover, our analysis not only highlights the observed failure modes, including language hallucination and visual illusion, but also deepens an understanding of these pitfalls. Our comprehensive case studies within HallusionBench shed light on the challenges of hallucination and illusion in LVLMs. Based on these insights, we suggest potential pathways for their future improvement.
The benchmark and codebase can be accessed at https://github.com/tianyi-lab/HallusionBench
Paper LinkMementos: A Comprehensive Benchmark for Multimodal Large Language Model Reasoning over Image Sequences
Multimodal Large Language Models (MLLMs) have demonstrated proficiency in handling a variety of visual-language tasks. However, current MLLM benchmarks are predominantly designed to evaluate reasoning based on static information about a single image, and the ability of modern MLLMs to extrapolate from image sequences, which is essential for understanding our ever-changing world, has been less investigated. To address this challenge, this paper introduces Mementos, a new benchmark designed to assess MLLMs' sequential image reasoning abilities. Mementos features 4,761 diverse image sequences with varying lengths. We also employ a GPT-4 assisted method to evaluate MLLM reasoning performance. Through a careful evaluation of nine recent MLLMs on Mementos, including GPT-4V and Gemini, we find that they struggle to accurately describe dynamic information about given image sequences, often leading to hallucinations/misrepresentations of objects and their corresponding behaviors. Our quantitative analysis and case studies identify three key factors impacting MLLMs' sequential image reasoning: the correlation between object and behavioral hallucinations, the influence of cooccurring behaviors, and the compounding impact of behavioral hallucinations.
Our dataset is available at https://github.com/umd-huang-lab/Mementos
Our paper is available at https://arxiv.org/abs/2401.10529
PARL: A Unified Framework for Policy Alignment in Reinforcement Learning
We present a novel unified bilevel optimization-based framework, PARL, formulated to address the recently highlighted critical issue of policy alignment in reinforcement learning using utility or preference-based feedback. We identify a major gap within current algorithmic designs for solving policy alignment due to a lack of precise characterization of the dependence of the alignment objective on the data generated by policy trajectories. This shortfall contributes to the sub-optimal performance observed in contemporary algorithms. Our framework addressed these concerns by explicitly parameterizing the distribution of the upper alignment objective (reward design) by the lower optimal variable (optimal policy for the designed reward). Interestingly, from an optimization perspective, our formulation leads to a new class of stochastic bilevel problems where the stochasticity at the upper objective depends upon the lower-level variable. To demonstrate the efficacy of our formulation in resolving alignment issues in RL, we devised an algorithm named A-PARL to solve PARL problem, establishing sample complexity bounds of order O(1/T). Our empirical results substantiate that the proposed PARL can address the alignment concerns in RL by showing significant improvements (up to 63% in terms of required samples) for policy alignment in large-scale environments of the Deepmind control suite and Meta world tasks.
Paper LinkRobustness, Adaptation & Generalization
Exploring and Exploiting Decision Boundary Dynamics for Adversarial Robustness
The robustness of a deep classifier can be characterized by its margins: the decision boundary's distances to natural data points. However, it is unclear whether existing robust training methods effectively increase the margin for each vulnerable point during training. To understand this, we propose a continuous-time framework for quantifying the relative speed of the decision boundary with respect to each individual point. Through visualizing the moving speed of the decision boundary under Adversarial Training, one of the most effective robust training algorithms, a surprising moving-behavior is revealed: the decision boundary moves away from some vulnerable points but simultaneously moves closer to others, decreasing their margins. To alleviate these conflicting dynamics of the decision boundary, we propose Dynamics-aware Robust Training (DyART), which encourages the decision boundary to engage in movement that prioritizes increasing smaller margins. In contrast to prior works, DyART directly operates on the margins rather than their indirect approximations, allowing for more targeted and effective robustness improvement. Experiments on the CIFAR-10 and Tiny-ImageNet datasets verify that DyART alleviates the conflicting dynamics of the decision boundary and obtains improved robustness under various perturbation sizes compared to the state-of-the-art defenses. Code here: https://github.com/umd-huang-lab/Dynamics-Aware-Robust-Training
Post on Social MediaAdversarial Auto-Augment with Label Preservation: A Representation Learning Principle Guided Approach
Data augmentation is a critical contributing factor to the success of deep learning but heavily relies on prior domain knowledge which is not always available. Recent works on automatic data augmentation learn a policy to form a sequence of augmentation operations, which are still pre-defined and restricted to limited options. In this paper, we show that a prior-free autonomous data augmentation's objective can be derived from a representation learning principle that aims to preserve the minimum sufficient information of the labels. Given an example, the objective aims at creating a distant "hard positive example" as the augmentation, while still preserving the original label. We then propose a practical surrogate to the objective that can be optimized efficiently and integrated seamlessly into existing methods for a broad class of machine learning tasks, e.g., supervised, semi-supervised, and noisy-label learning. Unlike previous works, our method does not require training an extra generative model but instead leverages the intermediate layer representations of the end-task model for generating data augmentations. In experiments, we show that our method consistently brings non-trivial improvements to the three aforementioned learning tasks from both efficiency and final performance, either or not combined with strong pre-defined augmentations, e.g., on medical images when domain knowledge is unavailable and the existing augmentation techniques perform poorly.
Project PageSketch-GNN: Efficient GNNs with Graph Size-Independent Scalability
Graph Neural Networks (GNNs) are widely applied to graph learning problems such as node classification. When scaling up the underlying graphs of GNNs to a larger size, we are forced to either train on the complete graph and keep the full graph adjacency and node embeddings in memory (which is often infeasible) or mini-batch sample the graph (which results in exponentially growing computational complexities with respect to the number of GNN layers). Various sampling-based and historical-embedding-based methods are proposed to avoid this exponential growth of complexities. However, none of these solutions eliminates the linear dependence on graph size. This paper proposes a sketch-based algorithm whose training time and memory grow sublinearly with respect to graph size by training GNNs atop a few compact sketches of graph adjacency and node embeddings. Based on polynomial tensor-sketch (PTS) theory, our framework provides a novel protocol for sketching non-linear activations and graph convolution matrices in GNNs, as opposed to existing methods that sketch linear weights or gradients in neural networks. In addition, we develop a locality-sensitive hashing (LSH) technique that can be trained to improve the quality of sketches. Experiments on large-graph benchmarks demonstrate the scalability and competitive performance of our Sketch-GNNs versus their full-size GNN counterparts.
Project PageVQ-GNN: A Universal Framework To Scale Up Graph Neural Networks Using Vector Quantization
Most state-of-the-art Graph Neural Networks (GNNs) can be defined as a form of graph convolution which can be realized by message passing between direct neighbors or beyond. To scale such GNNs to large graphs, various neighbor-, layer-, or subgraph-sampling techniques are proposed to alleviate the “neighbor explosion” problem by considering only a small subset of messages passed to the nodes in a mini-batch. However, sampling-based methods are difficult to apply to GNNs that utilize many-hops-away or global context each layer, show unstable performance for different tasks and datasets, and do not speed up model inference. We propose a principled and fundamentally different approach, VQ-GNN, a universal framework to scale up any convolution-based GNNs using Vector Quantization (VQ) without compromising the performance. In contrast to sampling-based techniques, our approach can effectively preserve all the messages passed to a mini-batch of nodes by learning and updating a small number of quantized reference vectors of global node representations, using VQ within each GNN layer. Our framework avoids the “neighbor explosion” problem of GNNs using quantized representations combined with a low-rank version of the graph convolution matrix. We show that such a compact low-rank version of the gigantic convolution matrix is sufficient both theoretically and experimentally. In company with VQ, we design a novel approximated message passing algorithm and a nontrivial back-propagation rule for our framework. Experiments on various types of GNN backbones demonstrate the scalability and competitive performance of our framework on large-graph node classification and link prediction benchmarks.
Project PageTuformer: Data-Driven Design Of Transformers For Improved Generalization Or Efficiency
Transformers are neural network architectures that achieve remarkable performance in many areas. However, the core component of Transformers, multi-head self-attention (MHSA), is mainly derived from heuristics, and the interactions across its components are not well understood. To address the problem, we first introduce a mathematically rigorous and yet intuitive tensor diagram representation of MHSA. Guided by tensor diagram representations, we propose a novel design, namely Tunable Transformers (Tuformers), by allowing learnable weights across heads, whereas MHSA adopts pre-defined and fixed weights across heads, as will be explained in our paper. Tuformers naturally reveal a flexible design space that a user, depending on her needs, can choose a structure that has either improved performance (generalization error) or higher model efficiency. Any pre-trained Transformer can be an initialization of the corresponding Tuformer with trainable number of heads for efficient training and fine-tuning. Tuformers universally outperform Transformers on various tasks across multiple domains under a wide range of model sizes, and their efficient variant in the design space maintains 93% performance using only 1.5% parameters.
Paper LinkUnderstanding The Generalization Benefit of Model Invariance From A Data Perspective
Machine learning models that are developed to be invariant under certain types of data transformations have shown improved generalization in practice. However, a principled understanding of why invariance benefits generalization is limited. Given a task, there is often no principled way to select “suitable” data transformations under which model invariance guarantees better generalization. This paper understands the generalization benefit of model invariance by introducing the sample cover induced by transformations, i.e., a representative subset of a dataset that can approximately recover the whole dataset using transformations. For any data transformations, we provide refined generalization bounds for invariant models based on the sample cover. We also characterize the “suitability” of a set of data transformations by the sample covering number induced by transformations, i.e., the smallest size of its induced sample covers. We show that we could tighten the generalization bounds for “suitable” transformations that have a small sample covering number. In addition, our proposed sample covering number can be empirically evaluated and thus provides principled guidance for selecting transformations to develop model invariance for better generalization. In experiments on CIFAR-10 and a 3D dataset, we empirically evaluate sample covering numbers for some commonly used transformations and show that the smaller sample covering number for a set of transformations (e.g. the 3D-view transformation) indicates a smaller gap between the test and training error for invariant models, which verifies our propositions.
Paper LinkScaling-Up Diverse Orthogonal Convolutional Networks With A Paraunitary Framework
Enforcing orthogonality in neural networks is an antidote for gradient vanishing/exploding problems, sensitivity by adversarial perturbation, and bounding generalization errors. However, many previous approaches are heuristic, and the orthogonality of convolutional layers is not systematically studied: some of these designs are not exactly orthogonal, while others only consider standard convolutional layers and propose specific classes of their realizations. To address this problem, we propose a theoretical framework for orthogonal convolutional layers, which establishes the equivalence between various orthogonal convolutional layers in the spatial domain and the paraunitary systems in the spectral domain. Since there exists a complete spectral factorization of paraunitary systems, any orthogonal convolution layer can be parameterized as convolutions of spatial filters. Our framework endows high expressive power to various convolutional layers while maintaining their exact orthogonality. Furthermore, our layers are memory and computationally efficient for deep networks compared to previous designs. Our versatile framework, for the first time, enables the study of architecture designs for deep orthogonal networks, such as choices of skip connection, initialization, stride, and dilation. Consequently, we scale up orthogonal networks to deep architectures, including ResNet, WideResNet, and ShuffleNet, substantially increasing the performance over the traditional shallow orthogonal networks.
Paper LinkARMA Nets: Expanding Receptive Field for Dense Prediction
Global information is essential for dense prediction problems, whose goal is to compute a discrete or continuous label for each pixel in the images. Traditional convolutional layers in neural networks, initially designed for image classification, are restrictive in these problems since the filter size limits their receptive fields. In this work, we propose to replace any traditional convolutional layer with an autoregressive moving-average (ARMA) layer, a novel module with an adjustable receptive field controlled by the learnable autoregressive coefficients. Compared with traditional convolutional layers, our ARMA layer enables explicit interconnections of the output neurons and learns its receptive field by adapting the autoregressive coefficients of the interconnections. ARMA layer is adjustable to different types of tasks: for tasks where global information is crucial, it is capable of learning relatively large autoregressive coefficients to allow for an output neuron's receptive field covering the entire input; for tasks where only local information is required, it can learn small or near zero autoregressive coefficients and automatically reduces to a traditional convolutional layer. We show both theoretically and empirically that the effective receptive field of networks with ARMA layers (named as ARMA networks) expands with larger autoregressive coefficients. We also provably solve the instability problem of learning and prediction in the ARMA layer through a re-parameterization mechanism. Additionally, we demonstrate that ARMA networks substantially improve their baselines on challenging dense prediction tasks including video prediction and semantic segmentation.
Paper LinkUnderstanding Generalization in Deep Learning via Tensor Methods
Deep neural networks generalize well on unseen data although the number of parameters often far exceeds the number of training examples. Recently proposed complexity measures have provided insights to understand the generalizability in neural networks from perspectives of PAC-Bayes, robustness, compression and so on. In this work, we take one step further to advance the understanding of the relations between the network's architecture and its generalizability. Using tensor methods, we present a data-dependent theoretical analysis of the generalizability for state-of-the-art (SOTA) neural network architectures from the compression perspective. Our analysis provides theoretical justifications for the empirical success and limitations of some widely-used tensor-based compression approaches. We further propose a practical layer-wise structure to improve the compressibility and robustness of current neural networks. With the proposed structure, an architecture similar to the SOTA Wide ResNet can be directly compressed (no fine tuning) by 8 times with only 0.56\% performance drop on CIFAR10 image classification. Our experiments also demonstrate that the proposed structure reduces the generalization error and improves the robustness of the SOTA method under label noise setting.
Paper LinkTensorial Neural Networks: Generalization of Neural Networks and Application to Model Compression
We propose tensorial neural networks (TNNs), a generalization of existing neural networks by extending (linear) tensor operations on low-order operands to multilinear operations on high-order operands. The problem of learning in general TNNs is challenging, as it corresponds to hierarchical nonlinear tensor decomposition. Therefore, we propose to address the learning problem by deriving the nontrivial backpropagation rules using the generalized tensor algebra we defined. Our proposed TNNs has three benefits over existing neural networks: (1) TNNs naturally apply to high-order input objects and thus preserve their multi-dimensional structures, as there is no need to flatten the data. (2) TNNs interpret advanced design of neural network architectures, including inception-like and bottleneck modules. (3) Mapping a neural network to TNNs with the same expressive power results in a TNN of fewer parameters. TNN-based compression of neural network improves existing low-rank approximation based compression methods as TNNs exploit two other types of invariant structures, periodicity and modulation, in addition to the low rankness. Experiments on LeNet-5 (MNIST), ResNet-32 (CIFAR10) and ResNet-50 (ImageNet) demonstrate that our TNN-based compression outperforms (5% test accuracy improvement universally on CIFAR10) the state-of-the-art low-rank approximation based compression under the same compression rate, besides achieving orders of magnitude faster convergence rates due to the efficiency of TNNs.
Sampling-Free Learning of Bayesian Quantized Neural Networks
Bayesian learning of model parameters in neural networks is important in scenarios where well-calibrated uncertainty estimates are important, such as active learning and reinforcement learning. In this paper, we propose Bayesian quantized networks (BQNs), quantized neural networks for which we learn a posterior distribution over their model parameters. We provide a set of efficient algorithms for learning and prediction in BQNs without the need to sample from their parameters. We demonstrate the effectiveness of BQNs for accuracy and uncertainty calibration on both MNIST and Fashion-MNIST classification benchmarks.
Paper LinkConvolutional Tensor-Train LSTM for Spatio-Temporal Learning
Higher-order Recurrent Neural Networks (RNNs) are effective for long-term forecasting since such architectures can model higher-order correlations and long-term dynamics more effectively. However, higher-order models are expensive and require exponentially more parameters and operations compared with their first-order counterparts. This problem is particularly pronounced in multidimensional data such as videos. To address this issue, we propose Convolutional Tensor-Train Decomposition (CTTD), a novel tensor decomposition with convolutional operations. With CTTD, we construct Convolutional Tensor-Train LSTM (Conv-TT-LSTM) to capture higher-order space-time correlations in videos. We demonstrate that the proposed model outperforms the conventional (first-order) Convolutional LSTM (ConvLSTM) as well as other ConvLSTM-based approaches in pixel-level video prediction tasks on Moving-MNIST and KTH action datasets, but with much fewer parameters.
Project PageLearning Deep ResNet Blocks Sequentially using Boosting Theory
We prove a multi-channel telescoping sum boosting theory for the ResNet architectures which simultaneously creates a new technique for boosting over features (in contrast to labels) and provides a new algorithm for ResNet-style architectures. Our proposed training algorithm, BoostResNet, is particularly suitable in non-differentiable architectures. Our method only requires the relatively inexpensive sequential training of T “shallow ResNets”. We prove that the training error decays exponentially with the depth T if the weak module classifiers that we train perform slightly better than some weak baseline. In other words, we propose a weak learning condition and prove a boosting theory for ResNet under the weak learning condition. A generalization error bound based on margin theory is proved and suggests that ResNet could be resistant to overfitting using a network with l1 norm bounded weights.
Paper LinkFoundation Models for RL

TACO: Temporal Latent Action-Driven Contrastive Loss for Visual Reinforcement Learning
📢Sample efficient #RL from #image observations with temporal action-driven contrastive learning
🚀40% performance boost than previous SOTA visual RL without a pre-trained policy or visual representation
Introducing TACO, an innovative approach set to overcome the prevalent challenge of sample inefficiency in reinforcement learning (RL) from raw pixel data. Traditional methods, focusing on self-supervised auxiliary tasks to enhance agent representations, often fall short in accurately learning optimal policy or value functions, especially in the context of continuous control with complex action spaces. TACO revolutionizes this space by employing a unique temporal contrastive learning strategy. It concurrently develops latent state and action representations by optimizing mutual information between current states paired with action sequences and their corresponding future states. This method not only encapsulates critical control information but also significantly boosts sample efficiency. Empirical results are striking: TACO achieves a remarkable 40% performance increase after one million interaction steps in nine visual continuous control tasks from the DeepMind Control Suite. Moreover, its versatility as a plug-and-play module enhances existing offline visual RL methods, setting new benchmarks in performance across diverse offline visual RL datasets. TACO is a game-changing tool in the realm of RL, promising a more efficient and effective path towards mastering complex visual control tasks.
🔗: Link to the paper https://arxiv.org/abs/2306.13229
Post on Social MediaSMART: Self-supervised Multi-task pretrAining with contRol Transformers
SMART: Paving the Way to AGI with a Foundation Model for RL in Sequential Decision-Making
Discover SMART, a cutting-edge foundation model that's revolutionizing the realm of Artificial General Intelligence (AGI) in Reinforcement Learning (RL). SMART stands out in the field of sequential decision-making, expertly handling the challenges posed by high-dimensional data and complex sequential controls. Its unique Control Transformer (CT) and innovative control-centric pretraining objective set a new standard for self-supervised learning. Our extensive research, validated through the DeepMind Control Suite, showcases SMART's unparalleled ability to enhance learning efficiency in a variety of tasks and domains. This includes impressive gains in both Imitation Learning (IL) and RL. Remarkably adaptive, SMART proves resilient to distribution shifts and performs exceptionally, even with lower-quality pretraining datasets. Embrace SMART, the cornerstone of next-gen AI, paving the way for AGI through transformative learning efficiency and adaptability in Reinforcement Learning.
The codebase, pretrained models and datasets are provided at https://github.com/microsoft/smart.
Post on Social MediaTransfer RL across Observation Feature Spaces via Model-Based Regularization
In many reinforcement learning (RL) applications, the observation space is specified by human developers and restricted by physical realizations, and may thus be subject to dramatic changes over time (e.g. increased number of observable features). However, when the observation space changes, the previous policy will likely fail due to the mismatch of input features, and another policy must be trained from scratch, which is inefficient in terms of computation and sample complexity. Following theoretical insights, we propose a novel algorithm which extracts the latent-space dynamics in the source task, and transfers the dynamics model to the target task to use as a model-based regularizer. Our algorithm works for drastic changes of observation space (e.g. from vector-based observation to image-based observation), without any inter-task mapping or any prior knowledge of the target task. Empirical results show that our algorithm significantly improves the efficiency and stability of learning in the target task.
Project PageTempLe: Learning Template of Transitions for Sample Efficient Multi-task RL
Transferring knowledge among various environments is important to efficiently learn multiple tasks online. Most existing methods directly use the previously learned models or previously learned optimal policies to learn new tasks. However, these methods may be inefficient when the underlying models or optimal policies are substantially different across tasks. In this paper, we propose Template Learning (TempLe), the first PAC-MDP method for multi-task reinforcement learning that could be applied to tasks with varying state/action space. TempLe generates transition dynamics templates, abstractions of the transition dynamics across tasks, to gain sample efficiency by extracting similarities between tasks even when their underlying models or optimal policies have limited commonalities. We present two algorithms for an "online" and a "finite-model" setting respectively. We prove that our proposed TempLe algorithms achieve much lower sample complexity than single-task learners or state-of-the-art multi-task methods. We show via systematically designed experiments that our TempLe method universally outperforms the state-of-the-art multi-task methods (PAC-MDP or not) in various settings and regimes.
Project PageCertifiably Robust Policy Learning against Adversarial Communication in Multi-agent Systems
Communication is important in many multi-agent reinforcement learning (MARL) problems for agents to share information and make good decisions. However, when deploying trained communicative agents in a real-world application where noise and potential attackers exist, the safety of communication-based policies becomes a severe issue that is underexplored. Specifically, if communication messages are manipulated by malicious attackers, agents relying on untrustworthy communication may take unsafe actions that lead to catastrophic consequences. Therefore, it is crucial to ensure that agents will not be misled by corrupted communication, while still benefiting from benign communication. In this work, we consider an environment with N agents, where the attacker may arbitrarily change the communication from any C<(N−1)/2 agents to a victim agent. For this strong threat model, we propose a certifiable defense by constructing a message-ensemble policy that aggregates multiple randomly ablated message sets. Theoretical analysis shows that this message-ensemble policy can utilize benign communication while being certifiably robust to adversarial communication, regardless of the attacking algorithm. Experiments in multiple environments verify that our defense significantly improves the robustness of trained policies against various types of attacks.
Post on Social MediaEfficient Adversarial Training Without Attacking: Worst-Case-Aware Robust Reinforcement Learning
Recent studies reveal that a well-trained deep reinforcement learning (RL) policy can be particularly vulnerable to adversarial perturbations on input observations. Therefore, it is crucial to train RL agents that are robust against any attacks with a bounded budget. Existing robust training methods in deep RL either treat correlated steps separately, ignoring the robustness of long-term reward, or train the agents and RL-based attacker together, doubling the computational burden and sample complexity of the training process. In this work, we propose a strong and efficient robust training framework for RL, named Worst-case-aware Robust RL (WocaR-RL), that directly estimates and optimizes the worst-case reward of a policy under bounded $ell_p$ attacks without requiring extra samples for learning an attacker. Experiments on multiple environments show that WocaR-RL achieves state-of-the-art performance under various strong attacks, and obtains significantly higher training efficiency than prior state-of-the-art robust training methods.
Project PageWho Is the Strongest Enemy? Towards Optimal and Efficient Evasion Attacks in Deep RL
Evaluating the worst-case performance of a reinforcement learning (RL) agent under the strongest/optimal adversarial perturbations on state observations (within some constraints) is crucial for understanding the robustness of RL agents. However, finding the optimal adversary is challenging, in terms of both whether we can find the optimal attack and how efficiently we can find it. Existing works on adversarial RL either use heuristics-based methods that may not find the strongest adversary, or directly train an RL-based adversary by treating the agent as a part of the environment, which can find the optimal adversary but may become intractable in a large state space. In this paper, we propose a novel attacking algorithm which has an RL-based "director" searching for the optimal policy perturbation, and an "actor" crafting state perturbations following the directions from the director (i.e. the actor executes targeted attacks). Our proposed algorithm, PA-AD, is theoretically optimal against an RL agent and significantly improves the efficiency compared with prior RL-based works in environments with large or pixel state spaces. Empirical results show that our proposed PA-AD universally outperforms state-of-the-art attacking methods in a wide range of environments. Our method can be easily applied to any RL algorithms to evaluate and improve their robustness.
Project PageUnderstanding the Role of Model Ensembles in Model-Based Reinforcement Learning
Probabilistic dynamics model ensemble is widely used in existing model-based reinforcement learning methods as it outperforms a single dynamics model in both asymptotic performance and sample efficiency. In this paper, we provide both practical and theoretical insights on the empirical success of the probabilistic dynamics model ensemble through the lens of Lipschitz continuity. We find that, for a value function, the stronger the Lipschitz condition is, the smaller the gap between the true dynamics- and learned dynamics-induced Bellman operators is, thus enabling the converged value function to be closer to the optimal value function. Hence, we hypothesize that the key functionality of the probabilistic dynamics model ensemble is to regularize the Lipschitz condition of the value function using generated samples. To test this hypothesis, we devise two practical robust training mechanisms through computing the adversarial noise and regularizing the value network's spectral norm to directly regularize the Lipschitz condition of the value functions. Empirical results show that combined with our mechanisms, model-based RL algorithms with a single dynamics model outperform those with an ensemble of probabilistic dynamics models. These findings not only support the theoretical insight, but also provide a practical solution for developing computationally efficient model-based RL algorithms.
Post on Social MediaTrustworthy AI

ELBERT: Adapting Static Fairness Notions to Sequential Decision Making
Decisions made by machine learning models may have lasting impacts over time, making long-term fairness a crucial consideration. It has been shown that when ignoring the long-term effect, naively imposing fairness criterion in static settings can actually exacerbate bias over time. To explicitly address biases in sequential decision-making, recent works formulate long-term fairness notions in Markov Decision Process (MDP) framework. They define the long-term bias to be the sum of static bias over each time step. However, we demonstrate that naively summing up the step-wise bias can cause a false sense of fairness since it fails to consider the importance difference of different time steps during transition. In this work, we introduce a long-term fairness notion called Equal Long-term Benefit Rate (ELBERT), which explicitly considers varying temporal importance and adapts static fairness principles to the sequential setting. Moreover, we show that the policy gradient of Long-term Benefit Rate can be analytically reduced to standard policy gradient. This makes standard policy optimization methods applicable for reducing the bias, leading to our proposed bias mitigation method ELBERT-PO. Experiments on three sequential decision making environments show that ELBERT-PO significantly reduces bias and maintains high utility.
Code is available at https://github.com/umd-huang-lab/ELBERT
Post on Social MediaTransfer Fairness Under Distribution Shifts
As machine learning systems are increasingly employed in high-stakes tasks, algorithmic fairness has become an essential requirement for deep learning models.
In this paper, we study how to transfer fairness under distribution shifts, a crucial
issue in real-world applications. We first derive a sufficient condition for transferring group fairness. Guided by it, we propose a practical algorithm with a fair consistency regularization as the key component. Experiments on synthetic and
real datasets demonstrate that our approach can effectively transfer fairness as
well as accuracy under distribution shifts, especially under domain shift which is
a more challenging but practical scenario.
An end-to-end Differentially Private Latent Dirichlet Allocation Using a Spectral Algorithm
We provide an end-to-end differentially private spectral algorithm for learning LDA, based on matrix/tensor decompositions, and establish theoretical guarantees on utility/consistency of the estimated model parameters. The spectral algorithm consists of multiple algorithmic steps, named as “edges”, to which noise could be injected to obtain differential privacy. We identify subsets of edges, named as “configurations”, such that adding noise to all edges in such a subset guarantees differential privacy of the end-to-end spectral algorithm. We characterize the sensitivity of the edges with respect to the input and thus estimate the amount of noise to be added to each edge for any required privacy level. We then characterize the utility loss of for each configuration as a function of injected noise. Overall, by combining the sensitivity and utility characterization, we obtain an end-to-end differentially private spectral algorithm for LDA and identify the corresponding configuration that outperforms others in any specific regime. We are the first to achieve utility guarantees under the required level of differential privacy for learning in LDA. Overall our method systematically outperforms differentially private variational inference.
Paper LinkGFairHint: Improving Individual Fairness for Graph Neural Networks via Fairness Hint
Graph Neural Networks (GNNs) have proven their versatility over diverse scenarios. With increasing considerations of societal fairness, many studies focus on algorithmic fairness in GNNs. Most of them aim to improve fairness at the group level, while only a few works focus on individual fairness, which attempts to give similar predictions to similar individuals for a specific task. We expect that such an individual fairness promotion framework should be compatible with both discrete and continuous task-specific similarity measures for individual fairness and balanced between utility (e.g., classification accuracy) and fairness. Fairness promotion frameworks are generally desired to be computationally efficient and compatible with various GNN model designs. With previous work failing to achieve all these goals, we propose a novel method
for promoting individual fairness in GNNs, which learns a "fairness hint" through an auxiliary link prediction task. We empirically evaluate our methods on five real-world graph datasets that cover both discrete and continuous settings for individual fairness similarity measures, with three popular backbone GNN models. The proposed method achieves the best fairness results in almost all combinations of datasets with various backbone models, while generating comparable utility results, with much less computation cost compared to the previous state-of-the-art model (SoTA).
Non-convex Optimization

SWIFT: Rapid Decentralized Federated Learning via Wait-Free Model Communication
The decentralized Federated Learning (FL) setting avoids the role of a potentially unreliable or untrustworthy central host by utilizing groups of clients to collaboratively train a model via localized training and model/gradient sharing. Most existing decentralized FL algorithms require synchronization of client models where the speed of synchronization depends upon the slowest client. In this work, we propose SWIFT: a novel wait-free decentralized FL algorithm that allows clients to conduct training at their own speed. Theoretically, we prove that SWIFT matches the gold-standard iteration convergence rate of parallel stochastic gradient descent for convex and non-convex smooth optimization (total iterations T). Furthermore, we provide theoretical results for IID and non-IID settings without any bounded-delay assumption for slow clients which is required by other asynchronous decentralized FL algorithms. Although SWIFT achieves the same iteration convergence rate with respect to T as other state-of-the-art (SOTA) parallel stochastic algorithms, it converges faster with respect to run-time due to its wait-free structure. Our experimental results demonstrate that SWIFT's run-time is reduced due to a large reduction in communication time per epoch, which falls by an order of magnitude compared to synchronous counterparts. Furthermore, SWIFT produces loss levels for image classification, over IID and non-IID data settings, upwards of 50% faster than existing SOTA algorithms.
Paper LinkEscaping From Saddle Points - Online Stochastic Gradient for Tensor Decomposition
We analyze stochastic gradient descent for optimizing non-convex functions. In many cases for non-convex functions the goal is to find a reasonable local minimum, and the main concern is that gradient updates are trapped in saddle points. In this paper we identify strict-saddle property for non-convex problem that allows for efficient optimization. Using this property we show that from an arbitrary starting point, stochastic gradient descent converges to a local minimum in a polynomial number of iterations. To the best of our knowledge this is the first work that gives global convergence guarantees for stochastic gradient descent on non-convex functions with exponentially many local minima and saddle points.
Our analysis can be applied to orthogonal tensor decomposition, which is widely used in learning a rich class of latent variable models. We propose a new optimization formulation for the tensor decomposition problem that has \name~property. As a result we get the first online algorithm for orthogonal tensor decomposition with global convergence guarantee.
Paper LinkEscaping from Saddle Point using Asynchronous Coordinate Descent
In this paper, we propose an asynchronous coordinate descent algorithm with a perturbation asynchronous subroutine, which can converge to second-order stationary point with high probability. The entire algorithm is an asynchronous parallel algorithm without any use of synchronous gradient update, and the number of time steps depends only poly-logarithmically on dimension. The convergence rate of this procedure matches the well-known convergence rate of gradient descent to second-order stationary points. When all saddle points are non-degenerate, all second-order stationary points are local minima, and our result thus shows that perturbed gradient descent can converge to a local minimum. To the best of our knowledge, this is the first global convergence result about asynchronous algorithm for non-convex settings.
Paper Link






