I. Robust Reinforcement Learning (Sequential Decision-Making) against Adversarial Perturbations
Y. Liang, Y. Sun, R. Zheng, and F. Huang, “Efficient Adversarial Training without Attacking: Worst-Case-Aware Robust Reinforcement Learning”, Neural Information Processing System (NeurIPS), 2022. Paper Link, Code Link, BibTex Link & Presentation Link.
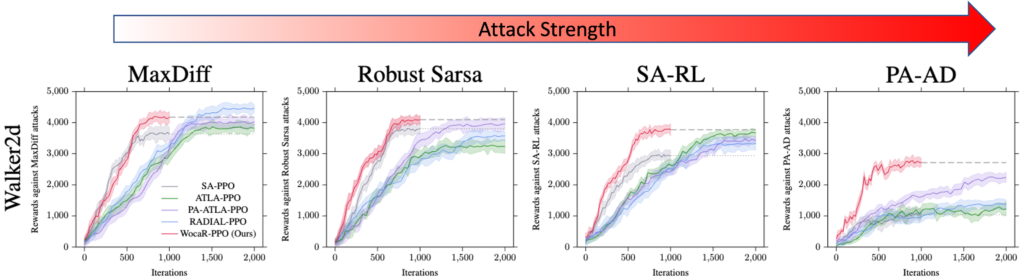
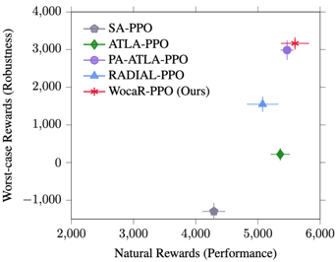
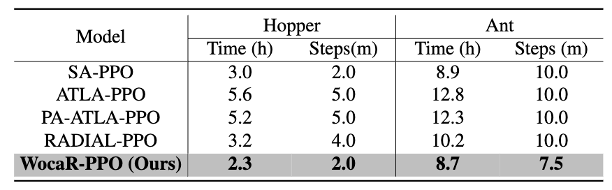
Recent studies reveal that a well-trained deep reinforcement learning (RL) policy can be particularly vulnerable to adversarial perturbations on input observations. Therefore, it is crucial to train RL agents that are robust against any attacks with a bounded budget. Existing robust training methods in deep RL either treat correlated steps separately, ignoring the robustness of long-term rewards, or train the agents and RL-based attacker together, doubling the computational burden and sample complexity of the training process. In this work, we propose a strong and efficient robust training framework for RL, named Worst-case-aware Robust RL (WocaR-RL) that directly estimates and optimizes the worst-case reward of a policy under bounded l_p attacks without requiring extra samples for learning an attacker. Experiments on multiple environments show that WocaR-RL achieves state-of-the-art performance under various strong attacks, and obtains significantly higher training efficiency than prior state-of-the-art robust training methods.
Are deep RL agents vulnerable?
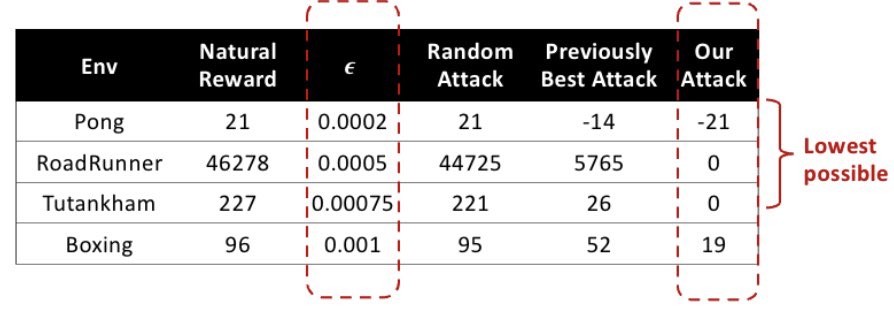
We all know deep neural networks are vulnerable to adversarially drafted perturbations which can even be imperceptible. How about deep RL agents? The answer is deep RL agents are even more vulnerable to adversarial perturbations. Using very small amount of perturbations, we can achieve the lowest possible reward in Atari Games.
Why are deep RL agents so vulnerable?
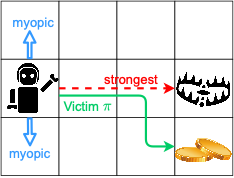
The answer if the long-term vulnerability. Deep neural networks powered value/policy networks causes vulnerabilities, but, in addition, a seemingly harmless action that renders an OK (or even good) immediate reward may cause catastrophic failure (i.e., destructive cumulative reward/value).
A myopic attacker may mislead the agent to the blue directions, but a strong attacker with long-term vision may lead the victim agent to the red path, which, initially, has good rewards.
So there is an urgent need to develop RL agents that are robust to adversarial perturbations.
SOTA Adversarial Training in Reinforcement Learning:
[ZCXLBH,’20] enforcing consistent output under similar inputs
Pros: fast Cons: worst-case value not considered
[ZCBH,’21] alternately train agent and attacker
Pros: considering worst-case Cons: slow, double the required samples