III. Efficient Graph Neural Networks for Large-Scale Graph
M. Ding, T. Rabbani, B. An, E. Wang, F. Huang, “Sketch-GNN: Efficient GNNs with Graph Size-Independent Scalability”, Neural Information Processing System (NeurIPS), 2022. Paper Link,Code Link, BibTex Link& Presentation Link.
Graph Neural Networks (GNNs) are widely applied to graph learning problems such as node classification. When scaling up the underlying graphs of GNNs to a larger size, we are forced to either train on the complete graph and keep the full graph adjacency and node embeddings in memory (which is often infeasible) or mini-batch sample the graph (which results in exponentially growing computational complexities with respect to the number of GNN layers). Various sampling-based and historical-embedding-based methods are proposed to avoid this exponential growth of complexities. However, none of these solutions eliminates the linear dependence on graph size. This paper proposes a sketch-based algorithm whose training time and memory grow sublinearly with respect to graph size by training GNNs atop a few compact sketches of graph adjacency and node embeddings. Based on polynomial tensor-sketch (PTS) theory, our framework provides a novel protocol for sketching non-linear activations and graph convolution matrices in GNNs, as opposed to existing methods that sketch linear weights or gradients in neural networks. In addition, we develop a locality-sensitive hashing (LSH) technique that can be trained to improve the quality of sketches. Experiments on large-graph benchmarks demonstrate the scalability and competitive performance of our Sketch-GNNs versus their full-size GNN counterparts.
Feeding model with large amount of data is often the key for success, but it’s not necessarily easy especially on graph data. Unlike images/languages in which we feed a mini-batch to the model for each round, it’s unclear how to select a mini-batch on a graph.
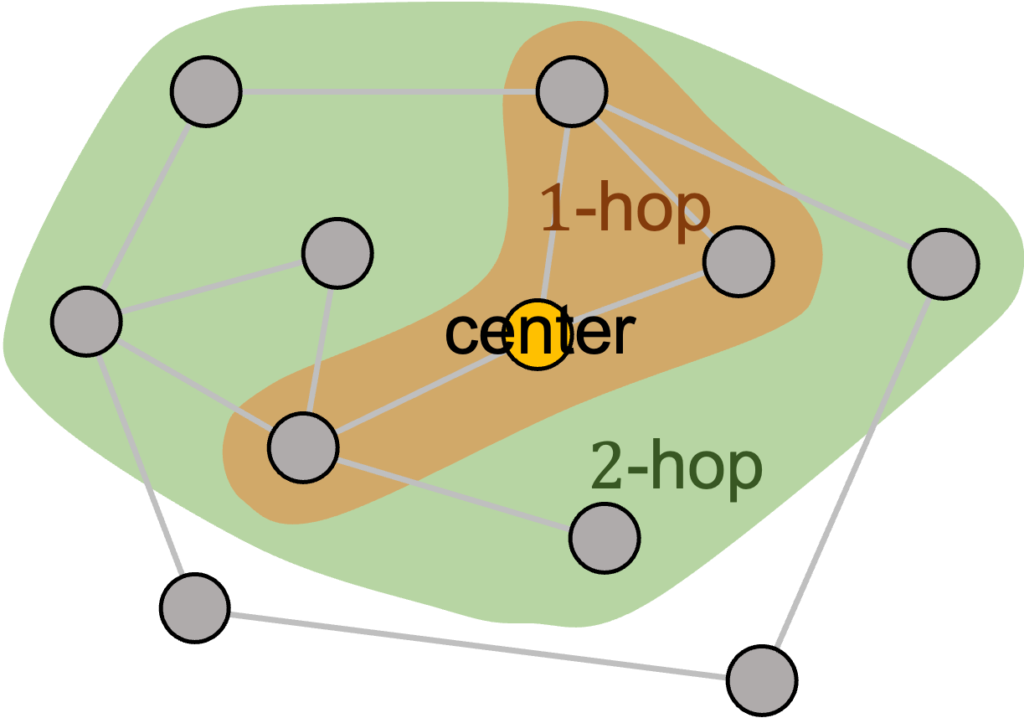
“Neighbor Explosion” Issue
A L-layer GNN (at least) aggregates information from all L-hop neighbors.
For scalability of GNNs to large graphs, existing methods are either (1) sampling-based or (2) historical-embedding-based.
Drawback: significantly increase computational time complexity in exchange for memory efficiency when scaling up to large graphs
Question: Can we develop a scalable training-framework of GNNs, both sub-linear computation and sub-linear memory cost in terms of number of nodes (i.e., graph size)?
An idea: apply count/tensor-sketching to graph convolution matrices.
However, this simple idea breaks when there are multi-layer nonlinear operators on top: sketch of nonlinear is not equal to nonlinear of the sketch. Therefore the nice theoretical guarantees that sketches are good approximations does not apply for multi-layer neural network.
A Fix: Polynomial Tensor-Sketch of Nonlinear Activations.
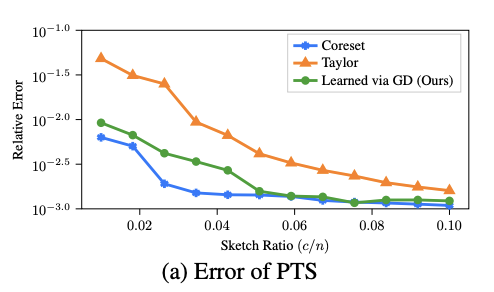
To solve this problem, we develop a polynomial tensor-sketch theory to approximate the nonlinear activations. We first expand the element-wise non-linearity σ as a power series, and then approximate the powers using count/tensor sketch. In polynomial tensor-sketch, there are some coefficients that need to be learned. Han et al. design a coreset-based regression algorithm, which requires at least O(n) additional time and memory. We propose learning the coefficients that optimize the classification loss directly using gradient descent with simple L2 regularization.
This Polynomial Tensor-Sketch of Nonlinear Activation technique is not restricted to graph and can be applied to general data. We derived error bounds on approximation power of the original data.
As a result, we propose Sketch-GNN, a training paradigm that training GNNs atop sketches to the graph adjacency and sketches of the node embeddings.
Sketch-GNN: Sketch Approximated Update Rule
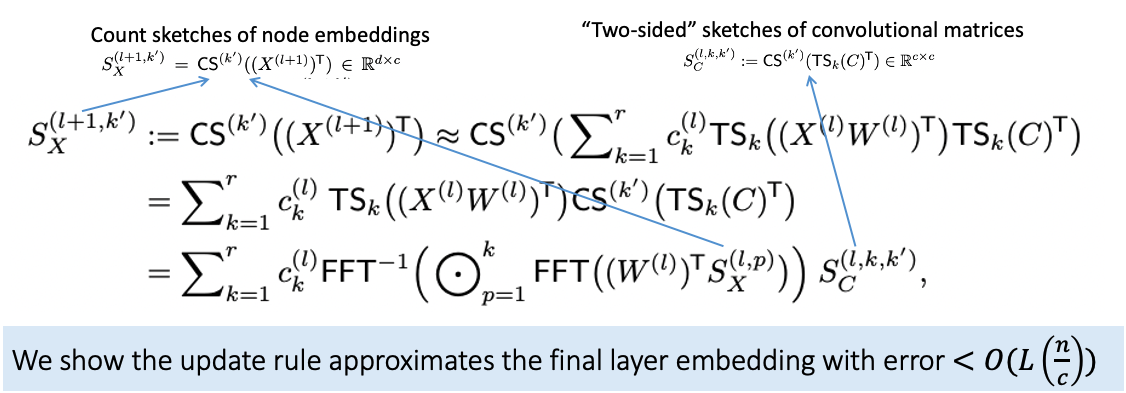
We apply count/tensor sketch to graph size dimension, so that GNN update rule can be approximated with sublinear complexity to graph size.
To improve sketch quality, we combine LSH with Sketching: data-dependent hash table.
Apply learnable LSH and sparse forward-pass/back-propagation techniques to online update the hash tables and avoid O(n) in loss evaluation.
Complexity of Sketch-GNN (where n is graph size, c is sketch size)
Training O(c)
Preprocessing O(n) [one-time cost]
Inference O(n)
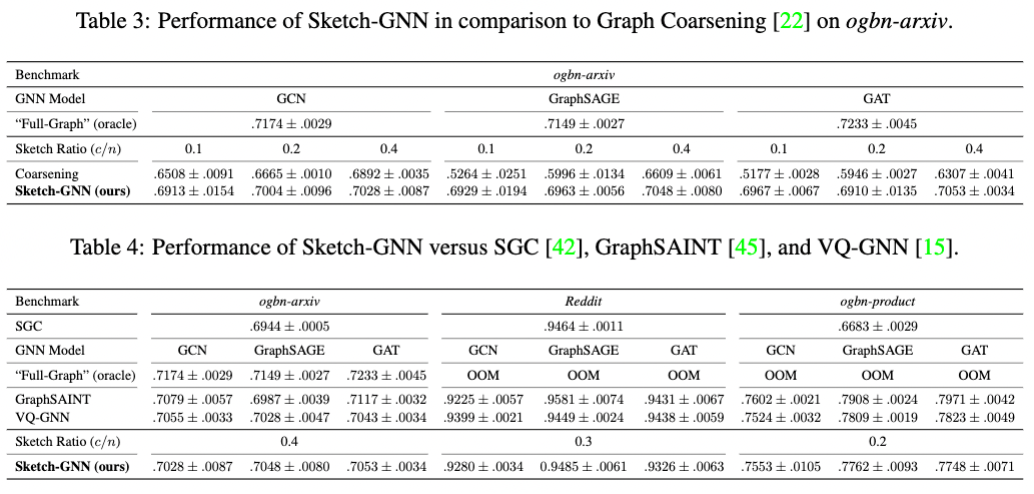
Experiments
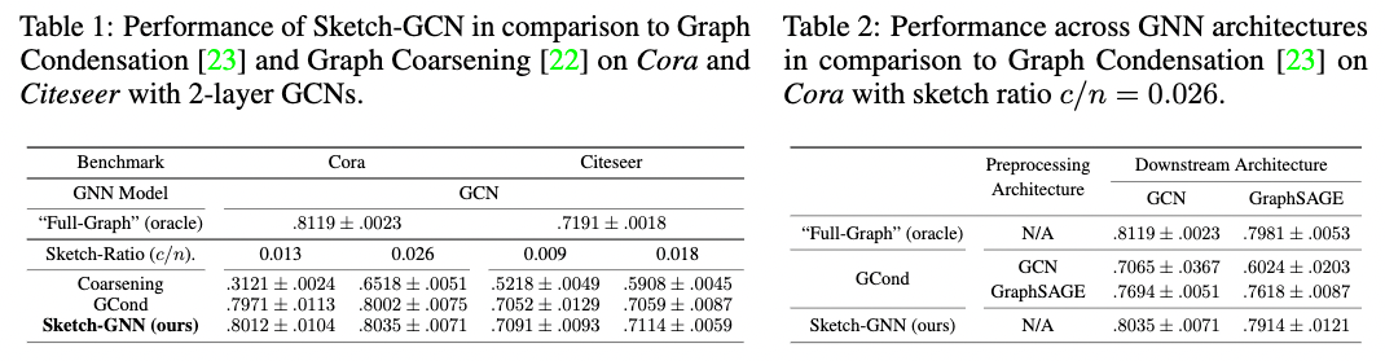
Sketch-GNN can outperform other sublinear training methods and generalize better across architectures.
Sketch-GNN can roughly match the full-graph training performance.